目录
[TOC]
1. Webpack能够帮Web前端工程化做哪些事
研发工程化是现代开发的必备基础,大部分流程进入工程化都可以极大地减少人为错误和提升效率。从研发流程上说,开发、代码拉取、检查、构建和部署发布都可以做工程化,这样的工程化工作往往需要一个系统来支撑,如亚马逊的apollo,腾讯的蓝盾。从编写代码上说,代码检查、补全、固定内容替换、压缩、混淆等都是工程化的一部分。webpack就是做代码工程化的工具之一。
Webpack的精细配置往往比较复杂,webpack4中已经简化了很多配置,用约定代替了部分配置。但在一些应用的极致优化中,还是需要对工程化的很多项做单独配置。下面以一个简单的移动端项目webpack构建后预发布的HTML页面为例,逐一讲解webpack在工程化中都做了哪些工作(当然,webpack能做比下例更多的工作)。
<!DOCTYPE html>
<html lang=zh-CN>
<head>
<meta charset=utf-8>
<meta content="width=device-width,initial-scale=1,maximum-scale=1,user-scalable=no,viewport-fit=cover" name=viewport>
<meta content=yes name=apple-mobile-web-app-capable>
<meta content=black name=apple-mobile-web-app-status-bar-style>
<link rel=icon href=https://cdn.cn/m/favicon.ico>
<meta name=Copyright content=Tencent>
<title>App Built By Webpack</title>
<link href=https://cdn.cn/m/assets/css/about.a2389654.css rel=prefetch>
<link href=https://cdn.cn/m/assets/css/home.83e6cc06.css rel=prefetch>
<link href=https://cdn.cn/m/assets/js/about.f9f934c9.js rel=prefetch>
<link href=https://cdn.cn/m/assets/js/home.05b64c92.js rel=prefetch>
<link href=https://cdn.cn/m/assets/css/app.2ce89ca8.css rel=preload as=style>
<link href=https://cdn.cn/m/assets/js/app.6f840142.js rel=preload as=script>
<link href=https://cdn.cn/m/assets/js/chunk-vendors.c8ba45a9.js rel=preload as=script>
<link href=https://cdn.cn/m/assets/css/app.2ce89ca8.css rel=stylesheet>
</head>
<body>
<noscript>
<strong>很抱歉,您当前的浏览器不支持Javascript,请先启用它来继续体验我们的产品。</strong>
</noscript>
<div id=app></div>
<script src=https://cdn.cn/m/assets/js/chunk-vendors.c8ba45a9.js></script>
<script src=https://cdn.cn/m/assets/js/app.6f840142.js></script>
</body>
</html>
以下只是简单说明webpack的工作,具体内容将在后面分别讲解。
这个HTML其实是只有一行的文件,为了让读者清晰地看到它的内容,我格式化了HTML标签,但在发布版本中它是一个没有缩进只有一行的size很小的HTML文件。
首先这个HTML是怎么形成的呢,它是通过webpack的一个插件“html-webpack-plugin”构建出来的。
你可能还会注意到里面有很多资源请求,请求的地址都是CDN服务器域名的地址,开发的时候肯定不会写这样的地址(难以更新文件测试代码),但是发布的版本就可以替换为请求CDN服务器的资源地址,这也是webpack帮我们做的,区别了不同环境,进行各自的工程化配置。
还可以看到,有些资源还带了版本号(为了服务器做缓存更新),这些版本号不会随着每次构建而改变,只有当资源内容变化了才会更新版本号。CSS文件也可以独立于JS文件,用contenthash做版本号,这样单页面的js变化也不会影响到css的缓存。
有些资源有preload属性,有些资源有prefetch属性,这是webpack帮我们区分了哪些资源需要提前加载,哪些要提前获取以让用户获得更好的体验。
一些第三方库的代码都被打包到了chunk-vendors这个文件中,它们被单独提取了出来。
如果你打开每个资源文件,还会发现这些文件都是经过压缩混淆的。其中JS代码还都是ES5语法的,不是开发时写的ES6语法代码。
当然,一些开发者还喜欢用typescript开发代码,但是浏览器并不能识别TS代码。webpack还可以将typescript的编译工作放进工程化的流程中。它不仅可以通过eslint对代码格式进行检查,还可以通过typescript的loader对代码进行编译。
这只是一个基本的移动端单页面的demo构建,如果用命令行让计算机分别做以上任务要写一个很长很长的脚本。这就是webpack诞生的原因,一个指令完成所有Web前端工程化的任务npm run build。
后面将会对这里提到的每一个webpack实现方式做详解,但在这之前,我们先来看一下,webpack的核心概念,模块化。
2. Webpack的模块化处理
2.1 Webpack术语概念
在说明webpack处理模块流程之前,先说明几个webpack的概念。
Entry
每一个Webpack项目都有一个或多个entry,这取决于Web应用是单页面还是多页面。顾名思义,entry就是webpack处理的入口文件,后续的一系列处理都从这个entry开始。
JS Module
JS模块规范比较多,如CommonJS,AMD,UMD,现在因为ES2015 Module的出现而逐渐开始统一,基本现在模块都是ES2015 Module和CommonJS的。现代开发者写的代码基本都是模块化结构的,从入口文件开始,代码调用了多个模块最终构建了一个完整的Web应用。
Chunk
Chunk是webpack打包成的代码块,主要用于处理构建bundle。从入口文件开始,如果不做任何其他处理,那么webpack就会将代码打包进一个chunk。如果是单页面应用,动态加载路由资源,那么每一个路由资源会被单独打包成一个chunk。如果项目做了代码分片,那么webpack还会从各个chunk中提取相同的部分形成新的chunk。Chunks与我们的应用没有直接关系,因为应用都是用下面的bundle来进行资源加载的。
Bundle
Bundle是独立可运行的捆绑包,通常一个bundle对应一个chunk或子chunks的集合。Bundle是对一个应用来说的概念,浏览器通过加载bundle来把webpack处理好的资源全部加载到App中去。
总结
一个chunk包含了多个JS modules,一个bundle又包含了一个chunk或多个chunk的一部分集合。bundle可以直接从chunk转化来,也可以通过动态加载import或common chunk split形成。
动态加载的方式为:
import(/* webpackChunkName: "lodash" */ 'lodash')
这样,webpack就会把lodash单独分离成一个chunk,并把这个chunk做成一个bundle让浏览器加载。
Common chunk split方式是从不同入口chunks中提取相同的模块做成新的chunk或合并到入口chunk中。如果做成新的chunk就会形成新的bundle,单独让浏览器加载。
下图是两个入口webpack打包处理示意图:
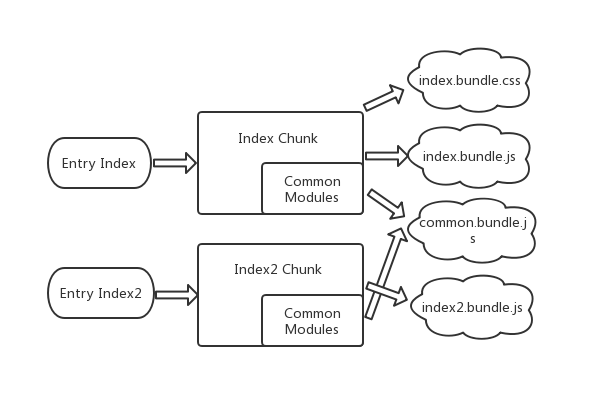
可以看到Index Chunk的部分内容分出去形成了三个bundle。
那么webpack到底是怎么处理各个modules的,bundle又具体是怎么构建的呢?下面就详细介绍一下webpack的模块处理流程。
2.2 Webpack模块处理流程
Webpack本质上就是一个javascript的模块打包器。通过开发者设定的入口文件,webpack建立了一个模块依赖图。这里的模块指的并非是CommonJS,也不是ES6 Module,而是说webpack自己的模块。Webpack为什么要拥有一个自己定义的模块实现方式呢?
在一个Web应用代码中,可能开发者引用了ES6 Module模块的JS文件,开发者还可能用了一个第三方的库,这个库是AMD模块化的,如requirejs。除了这些,开发者还有可能要用JS引入一个图片。这么多不同类型的模块如何在webpack下统一管理呢,这就是webpack自己实现其模块结构的原因。
它能够将多种不同的模块格式化为自己的模块结构并建立模块依赖图,它支持如下的模块:
- ES2015 Module (import,export)
- CommonJS (require(),module.exports)
- AMD (define,require)
- css中url引入的模块和img中src的模块
- ……
Webpack的模块结构与AMD、UMD、CommonJS和ES6 Module不是一个层面的关系,它将任意模块包装成它自己方便处理的数据结构。可以理解为,webpack的每一个模块里面包裹着任意上述js模块中的一种。至于代码执行层面的问题,那是babel的工作,babel可以将上述任意模块格式化为开发者指定的一种模块,大多数情况下都会为了兼容性转化为ES5的语法。所以不要将webpack的模块结构与js的模块结构弄混淆,上述的模块代码能运行是因为babel的处理,将不同模块代码转化为统一的语言,如ES5。而webpack的模块是为了方便让它统一管理打包的。我们看一个简单的例子。
/**
File: index.js
**/
var minus = require('./minus');
var add = require('./add');
var diff = minus(5, 3);
var sum = add(1, 2);
console.log('Diff = ' + diff);
console.log('Sum = ' + sum);
/**
File: add.js
**/
module.exports = function add(a, b) {
return a + b;
}
/**
File: minus.js
**/
module.exports = function diff(a, b) {
return a - b;
}
上面的代码都是CommonJS模块化的,在不做任何分块处理情况下,用webpack处理后(分块处理会将运行时部分代码分离出来):
(function (modules) {
// 模块缓存
var installedModules = {};
// webpack封装模块的方法
function __webpack_require__(moduleId) {
// 如果模块缓存中存在该模块,则直接返回
if (installedModules[moduleId]) {
return installedModules[moduleId].exports;
}
// 如果模块缓存中不存在,则新建一个并把它存在缓存中
var module = installedModules[moduleId] = {
// module Id
i: moduleId,
// 是否加载的标记
l: false,
// 模块exports
exports: {}
};
// 执行模块
modules[moduleId].call(module.exports, module, module.exports, __webpack_require__);
// 标记模块为已加载
module.l = true;
// 返回这个模块的exports
return module.exports;
}
...
// modules的第一个元素就是入口模块。
return __webpack_require__(0);
})
/************************************************************************/
([
// index.js
/* 0 */
function (module, exports, __webpack_require__) {
var minus = __webpack_require__(1);
var add = __webpack_require__(2);
var diff = minus(5, 3);
var sum = add(1, 2);
console.log('Diff = ' + diff);
console.log('Sum = ' + sum);
},
// add.js
/* 1 */
function (module, exports, __webpack_require__) {
var add = function (a, b) {
return a + b;
};
module.exports = add;
},
// minus.js
/* 2 */
function (module, exports) {
var minus = function (a, b) {
return a - b;
};
module.exports = minus;
}
]);
可以看到,最外层就是一个IIFE(立即调用函数表达式),参数modules就是这一个chunk涉及到的所有的模块,在下面调用处有定义。这样所有通过这个入口文件加载的模块都被加载进来了,如果有重复引入的地方,会直接从installedModules里返回exports。
如果是ES6的Module,要先经过babel的编译改成ES5的代码才能被webpack执行。但是整体的webpack模块打包方式是相同的。
最终,这些代码被打包整合到一个文件里-bundle,被浏览器加载。
这个bundle在浏览器中是怎么执行的呢?
- webpack打包后首先会形成自己的运行时代码,如
__webpack_require__方法的定义等,为模块执行和加载做准备工作。浏览器要先加载这些运行时的代码。 - 通过IIFE,浏览器执行第一个webpack模块,也就是开发者定义的入口文件的代码。
- 浏览器执行入口文件时会遇到很多JS模块的加载,通过
__webpack_require__方法会执行JS模块代码,JS模块又引用了别的模块,因此这是一个递归过程。期间不断注册新的installedModules并执行。 - 最后所有的模块执行完毕,代码执行流程一定会回到入口文件,执行到入口文件的最后一行,完成整个执行过程。
3. 非Javascript文件的处理-loader
上文描述的都是JS的处理情况,但是非JS的文件,webpack怎么处理呢?
比如在一个完整的项目中,开发者用了很多第三方的库和框架,它们的文件格式都不是js,内容也是千差万别,如Vue的单文件组件。那么webpack如何识别vue文件并进行后续打包处理呢?
这就需要loader来处理了,webpack的各种loader分别处理各种文件,如对vue而言的vue-loader。
Loader就是用于对源代码进行转换,然后输出给webpack它能识别的JS代码。
3.1 loader使用规则
Loaders可以内联调用,也可以在webpack.config.js里调用,下面的代码就是内联调用:
import Styles from 'style-loader!css-loader?modules!./styles.css';
这句代码就是指定用style-loader和css-loader来处理styles.css,将其转化为JS模块加载进来。
这种内联方式非常不方便,通常开发者会在config定义规则来匹配文件格式,进行加载,如:
module: {
rules: [
{
test: /\.css$/,
use: [
{ loader: 'style-loader' },
{
loader: 'css-loader',
options: {
modules: true
}
}
]
}
]
}
这种方式与上述内联代码作用是一样的,但是它却匹配了所有css文件,对所有css文件进行这两个loader的处理。
use属性是一个数组,是因为loader支持链式调用,数组最后一个loader最先处理匹配到的文件,并将处理后的内容传递给下一个loader。数组的第一个loader最后被调用,要输出javascript源码给webpack。也就是说,loader处理顺序是从下往上的。
对于链式调用的loader,严格地说,第一个输出给webpack的loader可以返回两个值,第一个是处理后的javascript源码字符串或buffer,第二个是可选的sourcemap,一个javascript对象。但loader的输入输出没有强制要求,如果一个loader专门是用来做最后一步处理的loader,那么这个loader就必须遵循上述规则。如果一个loader是用来做中间处理的,那么它的输入输出只需要能承接上下loader就可以了,这个往往需要做好loader之间的约定。而第一个处理的loader则必须是接受原始文件源码。
经过loader处理过的代码都是模块化的。这是webpack loader的强制性要求。
test是一个正则表达式,用于匹配这个loader使用范围。
每一个loader还可以有自己的options,用来让开发者自己选择具体的代码处理方式。
还有一些其他的方法,比如排除指定文件路径等,关于具体的module.rules,可以看官网文档。
3.2 loader还能做的更多
有了loader之后,开发者就可以加载各种非javascript资源了,但是,loader可以帮助开发者做更多的东西。
- 可以转译javascript语法,将开发者用ES6编程的代码输出为ES5通用兼容版本的代码。
- 如果开发者在编写javascript库,它还可以帮开发者将css加到库中,这样发布后,其他人引用这个库时只需要以模块化的方式import进来即可,无需单独再加载css。
- 可以对应用内所有静态资源增加版本号,以优化缓存,如,index.e3au67deu.css。
- 可以对页面引用CDN资源的链接自动加CDN域名的链接替换,包括css中的url请求。
- 可以对sass文件直接编译,输出css。
- ……
下面简单介绍几个常用的loader,具体使用方法可以查看下方链接。
babel-loader
babel-loader是很多项目都会用到的loader,它会把开发者写的各种版本的JS代码编译成指定版本的JS代码以适应各大浏览器的兼容性。
eslint-loader
eslint是代码检查工具,当多人一起开发时,eslint就尤为重要,再多的口头约定也比不上工具的强制规范。
css-loader
css-loader用来解析css文件中@import和url()。
sass-loader
sass-loader用来读取并解析scss文件为css文件。
…
Loader有太多了,根据项目需求不同可以加载不同的loader,这里不做赘述。当然,开发者还可以自己定义loader来满足工程化需求。
4. 代码的tree-shaking优化
4.1 Tree-shaking作用是什么
Tree-shaking是Web前端代码优化的一种方法,它跟DCE(Dead Code Elimination)有些相似但又不一样,根据RollUp的作者Rich Harris的说法,在Web前端代码构建中,DCE是代码打包好后进行优化代码。而Tree-shaking是在打包时,处理各modules时就删除掉了dead codes。
Tree-shaking的基础就是ES6的module,静态的特性使得代码分析成为可能,这也是为什么commonjs做不了tree-shaking。
看如下代码:
import test from 'utils/a.js';
console.log(test);
utils/a.js中的代码为:
export default {
a: 'flagAAAAA'
};
export const testB = {
b: 'flagBBBBB'
};
testB这个模块其实是没有用到的,如果没有任何工程化处理,那么打包的文件中会有testB这个无用的代码存在的。如果用webpack4做工程化处理,那么在构建production版本代码过程中,Tree-shaking会自动进行,进而删掉testB。
再来用class做一次webpack4构建代码实验:
import Test from 'utils/a.js';
utils/a.js中的代码为:
export default class {
a = 'flagAAAAA';
getA() {
return a;
}
redirect() {
window.location.href = '';
}
}
Test被引用进来但是没有被调用。
a.js的代码依然没有打包进去。
另一段关于模块引用的代码:
import Test from 'utils/a.js';
const t = new Test();
t[Math.random() > 0.5 ? 'getA' : 'redirect']();
utils/a.js中的代码为:
export default class {
a = 'flagAAAAA';
getA() {
return a;
}
redirect() {
window.location.href = '';
}
}
因为class中的redirect方法引入进来但是并没有确定一定使用,所以打包后的没有变化,redirect和getA方法依然存在。
4.2 无法Tree-shaking的情况
import { Add } from 'utils/a.js';
Add(1, 1);
utils/a.js代码为:
import { isArray } from 'lodash-es';
export function array(array) {
console.log('isArray');
return isArray(array);
}
export function Add(a, b) {
console.log('Add');
return a + b
}
因为array没有用到,所以按理说lodash-es不应该打包进来,但是tree-shaking还是打包了它。
可以使用插件webpack-deep-scope-analysis-plugin来解决这个问题。
4.3 代码副作用
代码副作用简单点来说,就是代码不确定性地在某处改变了某些东西,它会导致在一些情况会使tree-shaking无法准确的打包内容,只能保留全部代码。
如下面代码:
import { a } from './index.js';
console.log(a);
index.js有如下代码:
export { a } from "./a.js";
export { b } from "./b.js";
a.js有如下代码:
export const a = 'a';
b.js有如下代码:
(function() {
console.log('fun');
window.name = 'name';
})();
export const b = 'b';
虽然第一段代码只引用了a,但是打包代码中同样存在了b。这是因为b的代码中有IIFE(立即执行函数),虽然IIFE代码内容可能跟整个逻辑都无关,但是它不可以被删掉。这个就是函数副作用,因为没办法确定执行的内容会不会对其他代码产生影响,所以只能保留。
当然在Webpack4中提供了打包时可以强制忽略某一模块的方法。
4.4 Tree-shaking在Webpack4中使用方法
Webpack4默认在mode为production时开启了tree-shaking,省去了很多配置。
其中有一个配置项:sideEffects。
配置如:
{
name: 'your-project',
sideEffects: [
'./src/some-side-effectful-file.js',
'*.css'
]
}
开发者可以主动标记哪些文件为没有副作用的代码,这样webpack在处理时就可以直接按照引用关系来进行tree-shaking了。
具体使用方法见:sideEffects
5. Webpack工程化实践与优化
上面几个部分说明了一些原理和实现方法,用这些就可以对一个简单的项目进行webpack工程化处理了。
还是用第一章的Vue项目进行实践,讲解如何生成那样的HTML,下面会逐行注释说明,webpack4的配置如下:
// 一些必要的webpack插件
// HTML页面生成插件
const HtmlWebpackPlugin = require('html-webpack-plugin');
// 对JS文件进行混淆压缩的插件
const UglifyJsPlugin = require('uglifyjs-webpack-plugin');
// 最小化css并从js中提取单独成文件的css处理插件
const MiniCssExtractPlugin = require('mini-css-extract-plugin');
// css压缩处理插件
const OptimizeCSSAssetsPlugin = require('optimize-css-assets-webpack-plugin');
// vue单文件组件loader插件
const VueLoaderPlugin = require('vue-loader/lib/plugin');
const webpack = require('webpack');
const path = require('path');
// 一些项目自定义的环境变量
const localEnv = require('../env.js');
const PATHS = {
src: path.join(__dirname, '../src'),
dist: path.join(__dirname, '../dist')
};
// webpack4的配置
module.exports = env => {
return {
context: __dirname,
// 生产模式
mode: 'production',
// 构建入口文件路径
entry: {
index: `${PATHS.src}/pages/index.js`
},
// 输出路径、引用路径和文件名的设置
// chunkhash可以让它构建时根据内容来生成带有版本号的文件
output: {
path: path.join(PATHS.dist, 'static'),
filename: '[name].[chunkhash].js',
// 构建后html中引用路径,可换成CDN地址
publicPath: localEnv.cdn
},
// optimization是构建优化部分
optimization: {
minimizer: [
// 对JS进行uglify
new UglifyJsPlugin({
cache: true,
parallel: true,
extractComments: true,
uglifyOptions: {
ecma: 7,
compress: {
warnings: false,
drop_console: true
},
output: {
comments: /@license/i
}
}
}),
new OptimizeCSSAssetsPlugin({})
],
// 值 "single" 会创建一个在所有生成 chunk 之间共享的webpack运行时文件。
runtimeChunk: 'single',
// 分块优化,这里跟默认值差不多,具体分块优化见下面说明。
splitChunks: {
cacheGroups: {
vendors: {
test: /[\\/]node_modules[\\/]/,
name: 'vendors',
enforce: true,
chunks: 'all'
}
}
}
},
resolve: {
// 对于以下扩展名的文件中可进行别名命名,
extensions: ['.js', '.vue'],
alias: {
vue: path.resolve(__dirname, '../node_modules/vue/dist/vue.min.js'),
css: path.resolve(__dirname, '../src/resources/css'),
components: path.resolve(__dirname, '../src/components'),
...
}
},
// 各种loader
module: {
rules: [
{
test: /\.vue$/,
use: ['vue-loader']
},
// eslint编译
{
enforce: 'pre',
test: /\.js$/,
exclude: [
path.resolve(__dirname, '../node_modules/'),
path.resolve(__dirname, '../src/plugins/'),
path.resolve(__dirname, '../src/utils/'),
path.resolve(__dirname, '../src/sdk/')
],
use: [
{
loader: 'eslint-loader'
}
]
},
// babel编译
{
test: /\.js$/,
exclude: [
path.resolve(__dirname, '../node_modules/'),
path.resolve(__dirname, '../src/plugins/'),
path.resolve(__dirname, '../src/sdk/')
],
use: [
{
loader: 'babel-loader'
}
]
},
{
test: /\.css$/,
use: [
MiniCssExtractPlugin.loader,
{
loader: 'css-loader'
},
{
loader: 'postcss-loader'
}
]
},
{
test: /\.scss$/,
use: [
MiniCssExtractPlugin.loader,
// css处理
{
loader: 'css-loader'
},
// css预处理,如自动加浏览器兼容autoprefixer
{
loader: 'postcss-loader'
},
// sass编译
{
loader: 'sass-loader'
}
]
},
// 对于小于1KB的以下格式的文件直接进行base64的处理并进行hash版本化。
{
test: /\.(png|jpe?g|gif|svg)(\?.*)?$/,
use: [
{
loader: 'url-loader',
options: {
limit: 1000,
name: 'images/[name].[hash:7].[ext]'
}
}
]
},
{
test: /\.(woff2?|eot|ttf|otf)(\?.*)?$/,
use: [
{
loader: 'url-loader',
options: {
limit: 1000,
name: 'fonts/[name].[hash:7].[ext]'
}
}
]
},
{
test: /\.(ogg|mp3|wav|mpe)(\?.*)?$/,
loader: 'url-loader',
options: {
limit: 10000,
name: 'media/[name].[hash:7].[ext]'
}
}
]
},
plugins: [
// 生成最终HTML
new HtmlWebpackPlugin({
template: `${PATHS.src}/pages/index.html`,
inject: true,
chunks: ['runtime', 'vendors', 'index'],
filename: path.join(PATHS.dist, 'index.html')
}),
// 压缩提取css
new MiniCssExtractPlugin({
filename: 'css/[name].[chunkhash].css'
}),
// 创建编译时可以配置的全局常量
new webpack.DefinePlugin({
PRODUCTION: JSON.stringify(true),
VERSION: JSON.stringify('1.0.0'),
DEBUG: false,
SERVER_TYPE: JSON.stringify(env.SERVERTYPE)
}),
// 自动加载定义变量
new webpack.ProvidePlugin({
Vue: 'vue'
}),
new VueLoaderPlugin()
]
};
};
值得一提的是spiltChunks的优化,webpack4会自动提取出来一些chunks进行分块,根据下面这块代码:
cacheGroups: {
vendors: {
test: /[\\/]node_modules[\\/]/,
name: 'vendors',
enforce: true,
chunks: 'all'
}
}
Webpack会把node_modules下的代码中引用到的代码提取出来,以“vendor”命名他们,然后形成bundle让html加载。除了这个代码块优化外,其实最重要的优化是自定义的优化,根据自身业务不同,往往优化也会很不一样。
那么有没有一种完美通用的优化手段来规避webpack复杂的配置呢?个人觉得答案是没有的,其实webpack默认的配置已经可以满足一些中小项目的需求,但是要精细化优化,给用户较好体验的话,那么自定义优化是肯定要做的,统一的优化方法用webpack默认的就差不多了。通常对于工程师来说,使用一些已有的项目框架开始一个新项目是不错的选择,比如vue-cli,nuxt等,里面帮用户配置了绝大部分webpack选项,用户只需要按照约定做精细化配置和优化即可。
个人觉得比较合适的优化策略是,对于经常访问到的,同时页面发布周期较短的代码,应该把这部分代码分割成多个小文件,虽然会增加浏览器的并发请求数(HTTP2.0的多路复用可以较好的解决这个问题),但是可以极大的优化缓存命中。因为我们给资源加版本号,做代码分割优化就是为了让用户体验更好,访问更快。通过高命中缓存,用户可以拥有打开本地页面的体验。因为网站需要经常发布更新,所有被改动的带有版本号的文件会随着发布而失效,如果这个失效的文件带有太多公共代码,那么用户访问很多页面时,只要涉及到这个文件,就会重新发送请求。所以,对于这种高频访问的文件,应该尽量精细化。
其次,对于一些不是经常访问都会用到的低命中文件,应该尽可能采用动态加载的方式,减少浏览器请求负担。这种大文件如果不是有特殊需求,是不应该加到每次都需要访问的文件块中的,如路由分割的页面代码。因为用户一次浏览访问大概率不会访问全部页面,所以这种资源做preload更好。
说到preload,上面配置里并没有js资源的preload或prefetch,这些其实是在动态加载时设置的:
import(/* webpackPrefetch: true */ 'home');
其实优化是一个策略性的问题,从30分到80分的优化可能难度没那么大,但是80分到90分的优化可能要几倍于前者的精力与时间才能做到,有时可能因为业务原因还无法到达90分甚至更高的优化水平。当你优化了某一部分时,必然会损失某一部分,综合取舍,达到一个平衡才是个人认为较好的优化策略。
举例来说,对于一个详情页,如何优化才能给用户更好的体验(打开的更快,图片或视频更早出现在用户可视界面中等等)。方法有很多,比如在列表页时,当浏览器空闲时就提前加载详情页数据,但是要考虑用户命中问题,这需要取舍。也可以在客户端做列表页的缓存,每次进到列表页,如果参数等信息不变,那么直接返回缓存的页面给用户。还要考虑产品形态,是否主页或列表页有主推内容,这些主推内容是不是可以做资源预加载。
所以优化问题是一个长期的问题,只要产品有迭代,优化必然会一直伴随下去。当然,大部分的产品可能根本不需要那么高精度的优化,过度优化可能会让代码难以维护。找到一个最适合开发者所做产品的优化策略才是最好的优化。